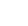近日,一種基于GPU并行的快速近場動力學算法,實現了計算力學算法與計算機技術的深入交叉結合,為解決傳統計算力學算法的效率問題找到了新的方向。
其成果發表在《計算力學學報》http://cjcm.ijournals.net.cn/jslxxb/ch/reader/view_abstract.aspx?flag=2&file_no=202410220000002&journal_id=jslxxb和《Engineering Analysis with Boundary Elements》https://doi.org/10.1016/j.enganabound.2025.106133。作者為深圳北理莫斯科大學楊楊副教授,與南方科技大學劉軼軍講席教授、碩士研究生蘇梓鑫。深圳北理莫斯科大學為第一完成單位。
近場動力學(Peridynamics)是一種有效解決斷裂問題的方法。然而,其非局部理論使得計算過程較為耗時。并行計算是加速數值計算的有效途徑,主要分為基于中央處理器(CPU)的并行計算和基于圖形處理器(GPU)的并行計算。CPU并行計算更適合處理邏輯復雜的場景,例如消息傳遞接口(Message Passing Interface, MPI)和共享內存并行編程(Open Multi-Processing, OpenMP)等。而GPU并行計算則更適合處理邏輯簡單但計算量大的場景,例如開放計算語言(Open Computing Language, OpenCL)和英偉達的統一計算設備架構(NVIDIA's Compute Unified Device Architecture, CUDA)等。由于近場動力學的非局部特性,每個材料點僅與其鄰域內的點相互作用,這使得其非常適合進行并行化處理。
目前,基于GPU的近場動力學并行研究,大多集中在將串行程序轉換為并行程序。許多優化策略帶來的加速效果主要依賴于GPU自身性能的提升,而針對GPU硬件結構的優化相對較少。此外,GPU并行計算仍存在一些問題:用于存儲鄰域點的內存空間沒有預設大小,導致線程和內存資源的低效使用,造成內存和計算資源的浪費,使得GPU在處理大規模問題時面臨挑戰;大多數GPU并行計算仍然嚴重依賴全局內存,未能充分利用CUDA的內存結構,導致內存帶寬的浪費;大多數近場動力學并行算法缺乏通用性,一些算法可能限制了鄰域的大小,僅能處理均勻分布且未受損的離散結構,或者限制了近場動力學理論的應用。
基于上述限制,本研究設計了一個成本效益高且性能優異的近場動力學模擬框架。該分析框架能夠以高效的計算速率準確模擬鍵基和態基近場動力學問題。該算法采用了粒子并行模式,建立了一個通用的鄰域生成模塊用以優化存儲,并提出了一種通用寄存器技術,用于高速訪問寄存器內存,減少全局內存訪問。該技術不僅消除了對鄰域點數量的限制,還適用于材料點的非均勻分布。與現有基于串行程序和OpenMP并行的近場動力學算法程序相比,該算法分別可實現高達800倍和100倍的加速。在典型的百萬級粒子模擬中,執行4000次迭代在單精度下可在5分鐘內完成,在雙精度下可在20分鐘內完成,這在低端GPU PC上即可實現。這意味著,在處理復雜的材料設計和損傷模擬時,研究人員能夠更快地獲得結果,從而加速科學研究和工程應用的發展。

圖1 通用寄存器優化算法示意圖
這項技術的廣泛應用將有助于推動多個領域的創新,特別是在需要高性能計算支持的行業中。通過利用消費級GPU的強大計算能力,研究人員能夠更高效地解決復雜的物理問題,從而推動科技進步和產業升級。
楊楊,博士,副教授,2023年9月加入深圳北理莫斯科大學材料科學系。主要研究方向為:計算固體力學、邊界元、近場動力學、機器學習等高性能算法開發,結構振動、斷裂、疲勞分析。